
什么是 RPC
首先思考这样一个问题,假设你不知道任何框架,现在有两台机器,每台机器上有一个服务,让你在其中的一个服务中调用另一个服务中的接口,怎么样才能做到呢?
RPC 全称为远程过程调用(Remote Procedure Call Protocol),通俗点来说,就是从一台机器通过网络调用到另一台机器的某个方法。
那这样说来的话,通过 Socket 调用另一台机器的 Sokcet 服务也是RPC,通过一些 HTTP 请求工具包调用一个远程 HTTP 接口也是 RPC 了。
最开始的 RPC 定义还有可能是这样的,但是这种方式太底层、太繁琐了。
现在的 RPC 除了要有明显的网络通信特征外,还要具备下面几个特点:
1、良好的封装:让我们感觉调用远程接口就好像是调用本地方法一样方便,封装底层网络通信的细节,让我们更专注于业务逻辑。
2、良好的协议设计:数据在调用方和提供方传输,数据组织要遵循约定好的协议格式,比如 HTTP 协议、TCP 协议这种。
3、高效的序列化和反序列化:远程调用,所以很大一部分开销来自于数据传输,所以原则上数据量越小越好,这就依赖于序列化的算法了。
封装的艺术(如何隐藏底层逻辑)
如果每次调用提供方提供的方法时都像下面这样繁琐,指明 URL、自己构造 JSON 序列化字符串等等,会不会不太方便。
public static final MediaType JSON
= MediaType.get("application/json; charset=utf-8");
OkHttpClient client = new OkHttpClient();
String post(String url, String json) throws IOException {
RequestBody body = RequestBody.create(json, JSON);
Request request = new Request.Builder()
.url(url)
.post(body)
.build();
try (Response response = client.newCall(request).execute()) {
return response.body().string();
}
}
而像 Dubbo 这样调用,如果没有接触过 RPC 的人,刚看到这段代码会感觉到好像就是在调用本地的一个方法。隐藏了很多的细节。
@DubboReference
private DemoService demoService;
String result = demoService.sayHello("world");
System.out.println("Receive result ======> " + result);
这就是现代 RPC 里一个很重要的特性,就是封装,尽量隐藏网络上的细节,让使用者感觉就是在调用本地的方法。
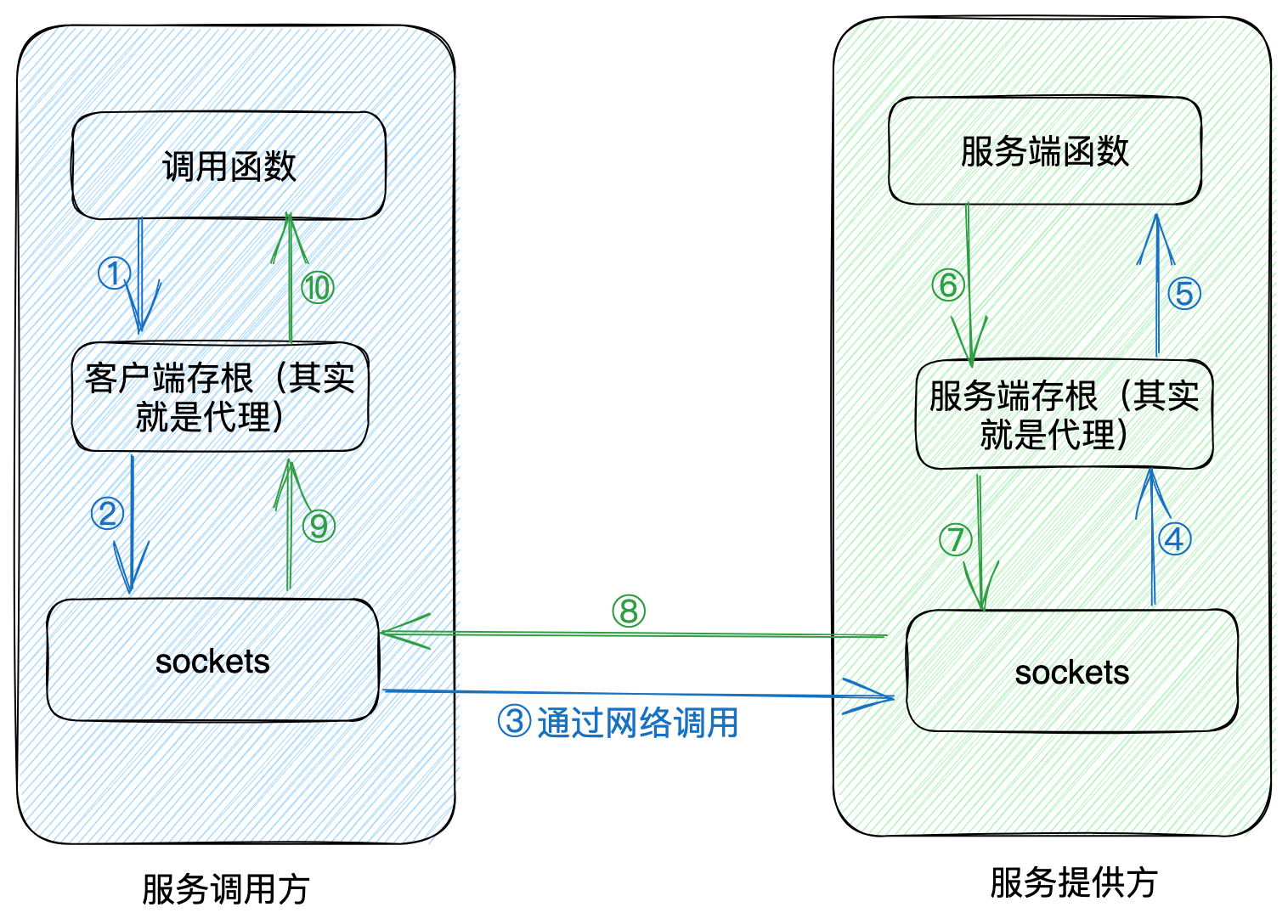
那在一般的 RPC 框架中,例如 Dubbo、GRPC等,是如何进行封装的呢。
我们看上面的图,其中调用方和服务提供方都有一个部分叫做存根(Stub),就是靠的它。听上去感觉这词不太容易理解啊,啥叫存根呢,其实说简单点儿就是一个代理方案。
举个例子,当我们调用本地的一个服务类的某个方法时,实际上这个服务类已经是一个代理类了,调用这个类的某个方法,实际上代理方法中可以加入很多额外的逻辑,比如构造 HTTP 请求、构造TCP 请求等等,最终穿过网络调用到真正的服务提供方的同名方法。
说到 Java 中的代理技术,相信大家都不陌生,有动态代理、静态代理,不了解的同学可以参考 Spring AOP 和 动态代理技术 这篇文章。
协议的实现
这里说的协议就是网络通信协议。远程过程调用嘛,那必须得通过网络传输才行,而通过网络传输那就得有遵行规定的协议。
这个协议是用来规范传输的数据的,所以它是一个应用层协议,比如 HTTP ,而不是传输层的协议,比如 TCP 、UDP 。
比如 GRPC 框架中用的协议是 HTTP2,Dubbo中可以选择多种协议,比如Hession、HTTP等。
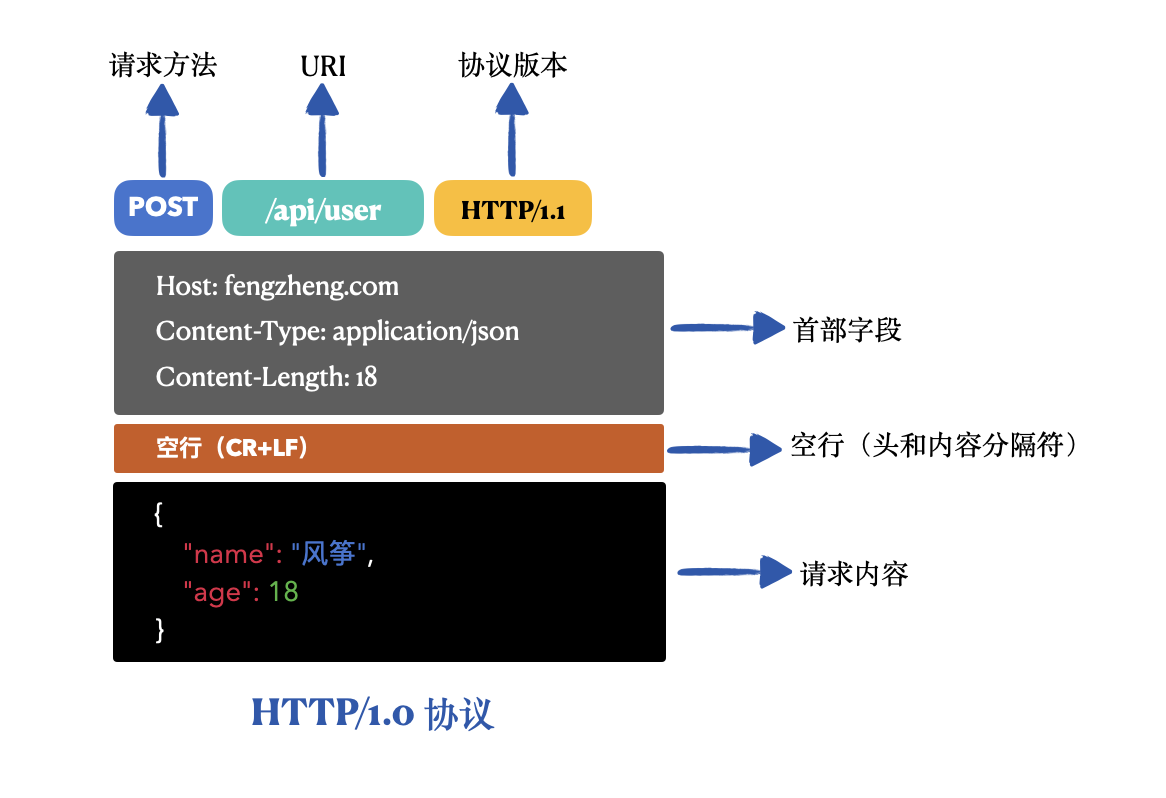
下图是 HTTP 1.0 协议的格式,包括首部和请求内容,首部可以指定请求方式、URI、版本、内容类型和长度等,内容部分就是真正要传输的数据, 如果是一个 RPC 调用的话,那就是�调用方法的参数和一些额外的信息(比如调用的方法名、类名等),首部和内容由一个空行分隔。
接收端可以根据空行了解哪些是头部,哪些是内容。
可以通过首部的内容长度字段来进行分配内存或其他操作。
其他的协议都有自己的格式,我们也可以自定义一个协议。如下是一个简单的协议格式:
通过魔术位可以直接判断是不是本协议数据,如果是的话,再进行处理。
通过整体长度和首部长度可以确定数据内容的长度,用来解析首部和数据。
通过序列化方式字段可以确定数据序列化采用的什么方式,用来实现反序列化。
| 0-8bit | 9-24bit | 25-32bit | 33-40bit | 不定长 |
|---|---|---|---|---|
| 标志位(魔术位) | 整体长度 | 首部长度 | 序列化方式 | 数据内容 |
一个 RPC 框架使用哪种协议是有权衡取舍的,如果考虑通用性那就可能使用 HTTP或者 HTTP2这种协议,比如 GRPC ,这样一来,可以在各种语言框架中通用,但是性能就稍微差一点了。
而如果从性能方面考虑呢,那就要牺牲掉一部分通用性了,比如Hession、Dubbo2协议,只有框架开发者提供了对应语言的版本,才能在相应的语言中使用。
序列化和反序列化(编解码)
上面说的协议主要指的是数据通信协议,而序列化和反序列化其实也要遵循一定的协议��。
说到序列化和反序列化,其实我们并不陌生。在Java开发中,经常会遇到。最常用的就是把 Java Bean 序列化为 JSON,将 JSON 反序列化为 Java Bean。
JSON 就是最常见的一种序列化和发序列化协议,其他的序列化方式还有 XML、GRPC 中用到的 Protocol Buffers。 Hessian 也有它自己的序列化算法。
为什么要有序列化呢,数据要想在网络中传输,那必须是二进制的形式。在远程调用里,我们像调用本地方法那样调用,使用的参数都是和当前项目语言一致的参数类型,比如Java中的 String、List、Map等等,那要把这些类型转换成二进制,靠的就是序列化算法。
JSON 和 XML 这种文本序列化方式比较简单,使用场景非常广泛,通用性强,但是序列化后产生的二进制体积也比较大,这样在传输的时候就会比较耗时、占用带宽。
而像 Protocol Buffers 这种序列化方式,它使用结构化的消息定义语言(IDL)来定义数据结构和服务接口,支持多种编程语言,而且序列化后的二进制也会最大程度的压缩,少占用带宽,有很高的传输效率。
总结
下图是整个 RPC 调用过程的简化版。
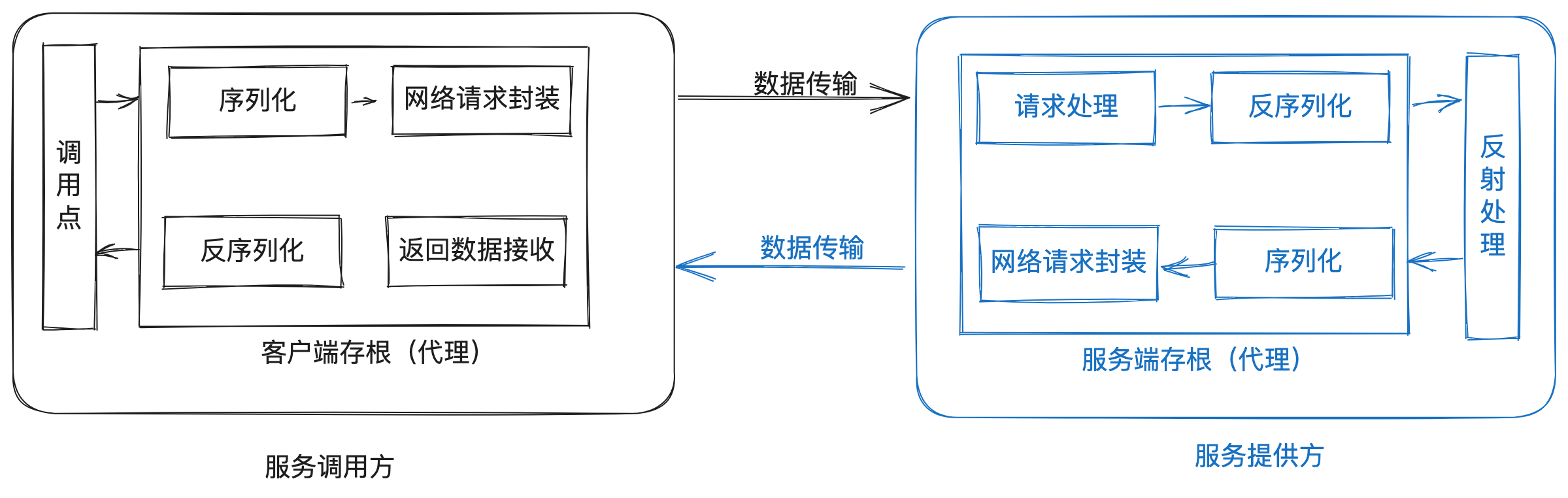
序列化和反序列化功能会在代理中进行,在很多框架中也称这部分为编解码。
封装的网络请求既有可能是 HTTP 请求,也有可能是 Sockets 请求,比如有很多 RPC 功能都使用 Netty 作为通讯层。
除了主要的功能外,一个成熟的 RPC 框架还有考虑诸多其他因素,比如性能、安全性、兼容性等等。
